How VLA-0 Compares
We categorize existing VLAs into three families. VLA-0 takes the simplest approach.
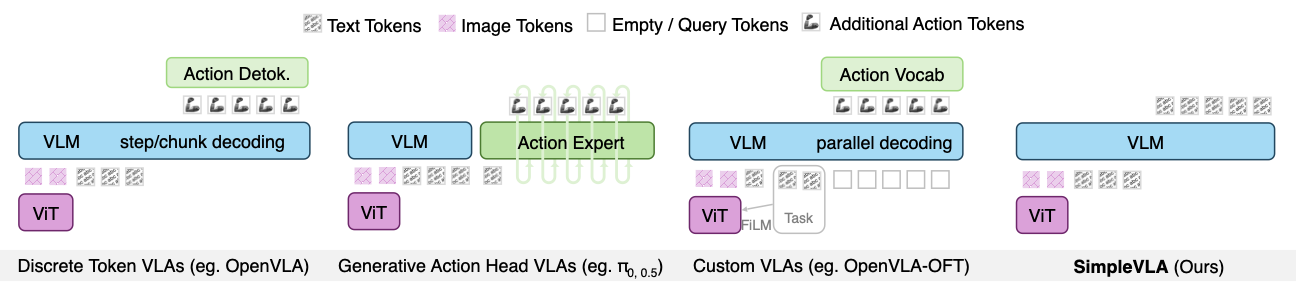
Discrete Token VLAs
Examples: RT-2, OpenVLA
- Discretize actions into bins
- Assign tokens from VLM vocabulary
- ⚠️ Limited action resolution
- ⚠️ Compromises language understanding
Generative Action Head VLAs
Examples: π₀, SmolVLA
- Attach action generation head
- Use diffusion or flow matching
- ⚠️ Requires new neural network
- ⚠️ May degrade VLM capabilities
Custom Architecture VLAs
Examples: OpenVLA-OFT, π-FAST
- Specialized modifications
- Custom tokenizers
- ⚠️ Significant changes
- ⚠️ Complex training pipelines
VLA-0 (Ours)
Zero modification approach
- ✓ Actions as text (integers)
- ✓ No vocabulary changes
- ✓ No architectural changes
- ✓ Arbitrary action resolution